




大連のドローンショーのプロモーション撮影に参加しましたっ!

お久しぶりですっ ふむひみです\(^o^)/
過去記事になりますが、御縁あって大連のドローンショーに参加させて頂きました!
紹介動画を作ったので大連行く人は是非とも見てください!
僕のオススメ!✨ギークハウス新宿2とは🏠💻

どうも!超お久しぶりですっ🌟
相変わらず日本に帰れず中国で引きこもってるふむひみです\(^o^)/
今日は僕が、未経験エンジニアとして初上京した時にお世話になったシェアハウス(GEEK HOUSE新宿2)について紹介したいと思います!
一番下にそもそもGEEK HOUSEとは何かまとめてるので、ちらっと見てみてください!
GEEK HOUSE新宿2がおすすめな理由

1.家賃が安い(割引や飯が無料になるサービスがある!)
まず僕が上京する際、決め手になった理由でもありますが、家賃が安いです。
4人部屋ではありますが、一人1ベッドで都心・新宿で家賃が5万5000円という超格安物件
また、プログラミングなど何かしらのスキルを持っているもしくは勉強してると認められた場合5000円割引になり、なんと家賃5万円になります。
更に、米とパスタが無料なので、超節約できます🍚!!

2.新宿3丁目駅に徒歩5分
交通アクセスが神です。
なんと、徒歩5分で丸の内線・副都心線・都営新宿線にアクセスできます。家賃5万円でw
なので、移動が多い方や毎日通勤される方にもおすすめです。

3.技術書がいっぱい置いてある
エンジニアやデザイナさんで普段から勉強されてる方が多いと思います。
そういう方々って毎回技術書など買う際に高いと感じたこともおおいのではないかと
そんな人々のためにギークハウスでは技術書をシェアするシステムが整っており、本棚から本を借りることができます。
また、他のギークハウスにある本などもslackを通して連絡し、借りることができます。

4.作業部屋が多い・作業用モニターなど借りれる
普段から勉強や在宅ワークされる方にとって作業部屋とモニターは必需品ですよね。
そういう作業部屋が多く、モニターも借りれます。椅子もしっかりPC作業で腰痛などにならないように配慮されており最適な作業環境を提供してるようです。
気分転換に別部屋で作業するのも効率アップに繋がります。

5.新宿御苑まで徒歩10分
東京都心に上京してからランニングする場所や公園が少なく困ったことはありませんか?
僕も大阪から上京したのですが、走れる場所がなくはじめの頃はだいぶ困りました。
ジムに行くのもいいけど、やっぱり自然豊かな場所で散歩したり走ったりリフレッシュしたいですよね。
ギー2はなんと新宿御苑からめちゃくちゃ近いんです。
なので、東京で消耗されてる方は新宿御苑で癒やされてみてはいかがでしょうか?
入場料は1回500円・年間パスポートは2000円でジムに行くより余裕で元が取れます。

6.住宅周辺がアングラ感ある
ここは好き嫌い分かれると思いますが、住んでる場所が新宿でも特殊な雰囲気を醸し出してる場所なので面白いことに遭遇しがちです。
初めて上京した時は異世界に転生した気分を味わえました。
また、歌舞伎町やゴールデン街が近く、ハロウィンやその他イベントデーは周りに仮装した人があつまったり、道端で酔いつぶれてる人がたくさんいたり"新宿メルトダウン"をじかに味わうことができます。
人生に飽き飽きしてるつまらないと感じてる人は一度異世界転生してみてはどうでしょうか?

最後に
最近は部屋の掃除が活発に行われており、住民をもっと募集しようとしてるみたいです。
ご興味のある方は東京に来た際には一度立ち寄ってみてはどうでしょうか?
こちらから連絡してみてください!
そもそもGEEK HOUSEとは?
ギークハウスとはギークハウスプロジェクトという企画から始まっており、エンジニアやクリエイターその他いろんな特徴がある方や興味ある人が集まりシェアハウスをするというプロジェクトです!
中国でリモートワークするのはとてもしんどい件

どうも お久しぶりです!
今年頭にブログやyoutubeを投稿して以降、ちょっとさぼり気味で全然投稿していませんでした💦
サイバー大学生がオンライン勉強会やるってよ(通称:オンやる)が2020年からプレスタートしたので、それに合わせて今月来月あたりにちょこちょこ投稿していきますね!!☆
自己紹介
今回僕のブログを見てくださる方で僕のことをよく知らない人もいるでしょうし、軽く自己紹介させていただきます(^^)/
大学1年生終了→英語留学→
中国・香港でインターンシップ→
サイバー大学に転入→webエンジニア1年
→フリーランスとして独立
現在、サイバー大学4年生で仕方なく中国で生活しながら、お察しの通り雑魚プログラマをしてます(笑)
なぜ中国にいるのか
僕が中国に来た経緯として2019年こちらのブログを書きました
このブログにも書かれている通り、日本しんどいわ~(´;ω;`)ってなって香港経由で中国深圳に入りました。
そして、五年ぶりぐらいに福建省(ウーロン茶の名産地?)の親戚に会いに旧正月だけ(今年は1月真ん中から末当たりまで)新幹線で行ったのですが、一緒にコロナも来てしまいました。
その時の中国政府の対応は素早く、周りのおじいちゃんおばあちゃん勢の対応も爆速
やっぱり、一回サーズを経験してるだけみんなの慎重度は大したものでした。
まあ、日本で想像してもらうと、今のコロナより殺傷力が強いウイルスが出て、数年後に似たようなウイルスが出たら日本政府も一般市民も普通に焦って早急な対応をしますよね。そういう感じです。
それにしても、さすが中国人これはちょっとやりすぎなのでは??という方法でコロナ予防もしてます。
これは僕が実際に老人が多めのマンション街で撮った写真です。

シェアリングバイクを壁にするという斬新な方法
昔、ちょっとCMで見かけた"かたまりだましい"っていうゲームを思い出した。(笑)
まあ、そんなこんなで日本からリモートでちょっと仕事をもらったり、なんとかしながら6月までは仕事があったのですが7月のフルリモートの案件で中国では無理だと発覚しました。
そこから会社の人と話合い8月に日本に帰ることで合意し、そんなこんなで上海の空港に向かってからまさかの飛行機キャンセルが発覚。
ちゃんと、『旅行の準備を始めましょう』的なメールが来てたのにも関わらず、そういう問題になってしまいビザも切れたのでとりあえず領事館に言われるがまま住所登録してある福建省に早急にかえってきたのですが、資料の日本語翻訳をしたりいろいろ手続きが多くまだしばらく不法滞在者生活は続きそうです💦(笑)
まあ、そんなこんなして『中国でリモートはやっぱり無理やわ~。やっぱり、日本帰ろっと』って思ってた矢先の出来事なので中国で本当にリモートワークが不便なだわっていう愚痴を含め説明していこうと思います(笑)
前置き無駄に長くてごめんね(笑)🙇
中国でリモートワークまじでだるいという話
だるいその1(日本で使えていたSNSやgoogleが使えない)
まず、中国来てから早速困ったのがtwitterやfacebookやlineなどが使えないということ。
もちろん、サイバー大学の授業を受けるときもVPNをつけて受けないといけない。
数回中国に来ていて、ある程度慣れていたがそれでもだるい。
とりあえず、事前に日本でVPN(virtual private network)を準備して来ていたがやっぱりVPNでも中国で使えない物が多く、使えても速度がめっちゃ遅いなんてざら
おすすめのVPNはこちらの記事の下あたりに書いてるように世界VPNやExpressVPNなどがおすすめです。後、最近つかってるのでカベネコVPNがおすすめ!
中国に短期旅行で来るなら基本的に、どのVPNも1週間から1か月ほどお試し期間があるのでそれで乗り切りましょう
もし1カ月以上長期の旅行になるならexpress VPNや世界VPN など1か月以上3か月未満のサービスを使いつつ、切れてしまったら有料でも速度が速くて安定性の高いVPNサービスをおすすめします!
ExpressVPNの注意点として僕が使ってた時はシンガポールのサーバー経由がメインで、日本のサーバー経由がないのではてなブログなどの海外サーバーからセキュリティ上アクセスdenyされてるサービスを見たりできないのでそういうサービス使ってる人は世界VPNなどの日本経由のものを選ぶといいと思います。
ほかに使えるもの
ios スマホでは無料で使えるネコVPNで十分です!おそらく、appleストアにまだあるはず!
それ以外に、shadow roket ,カスペルスキーセキュアコネクションなども無料期間長くて使えた記憶があります。
だるいその2(ネットスピードが遅い)
ホテルで住む場合などは基本的に、備え付けのwifiがあると思いますが、こちらで一度速度を測ってみましょう。
中国ローカルでの速度はこちら
海外サイトや日本でのサイトの速度を見る場合はこちら
中国では250mbpsぐらいあっても、VPNを通して日本の方の速度を測ると、40mbpsぐらいに落ちます。
これが非常に厄介
夜の9時から1時ぐらいまでインターネットのアクセスが増えるのでさらにおそくなり、日本のサイト見るのに2mbpsぐらいになったりします。
酷い時だと、youtube見るときは画質を144pぐらいにしないと見れないです。
サイバー大学の授業とかまじでこの時間は受けれない。基本先生がみんなフリーズしてまじでわい氏苦笑いしかできなかった(;´д`)トホホ
前は、中国移動のネットワークを今は、中国電信のネットワークを使ってますが毎月1000円多めに払うと、最大1000mbpsのやつがあると聞いたのでそれにしようか悩み中
基本的に、インターネット契約は日本より安いけど、日本と同様快適にネットサーフィンするならVPN含め結局中国でも日本と同じぐらい値段を払わないといけないのではと思う。
だるいその3(VPNがあっても、Googleのサービスを使えない場合がある)
この中国だるいあるあるが本来日本に帰る羽目になった原因なんだけど、本来7月からベンチャーでfirebaseを使った案件をさせてもらえる機会を頂いた。
javascript自体今年からやっと真面目に触りだしたので、node.js自体あまり触ったことがないのも含め事前に練習でサイバー大学のグループ管理リストサイトを作ろうとしていた中あることが発覚した。
cloud functionを使ったdeployが異様に遅い。日本でfirebase使ったことがないから比較はできないけど、普通に使い物にならないぐらいdeployが遅かった。
また、firebase loginする際も、VPN をつかってるし、IPアドレスが変わってしまうからか毎回違うlogin tokenを発行してそれを元にloginしないといけず、作業にならなかった。
4月にreact とgatsby jsを使ったサイトを作ったときは、全然こういうことがなかったのでVPNがあってもGoogleのサービスをちゃんと使えないのはかなり衝撃的だった。
redditなどで、外国人が同じ質問してて、結局AWS chinaやアリババクラウドを推奨してる模様。
まあ、どちらにしろ日本に帰れなくなったので仕事は縁がなかったことででなくなりました(´;ω;`)
だるいその4(中国でwindows home のPC買ったら、システム言語変更できない)
サイバー大学入学時に買ったおフルのmacbook Proの液晶がおかしくなり、急にシャットダウンすることも増えたので新しいPCを買おうと考えていた。
初めのうちはwindows使いにくいし、なんかよくわからんとおもってたが、あまりにも金がないのと、2020年からwsl2でネイティブのLinuxが使え、docker for desktopがwindowsでもしっかり動くし、windows terminalも入ったのを含めmacbookじゃなくてよくね!?ってなり、かっこいいdual monitorのwindows Laptop を買おうと思い立った!
日本帰って買うつもりだったけど、税金を計算すると1万5千円以上違ってくるので、結局中国で買ったのですが失敗でした。
まさかのwindows homeが普通のhomeではなく、謎のwindows home chinese editionという言語設定を中国語以外に変更できないというクソ仕様でした(笑)
イメージとしてこういう感じ
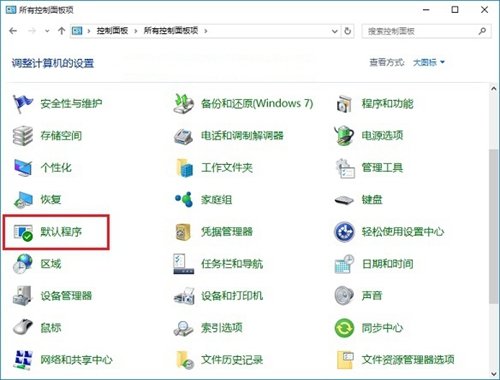
ここぐらいならまだ何とか理解できるけど、まじで細かい設定になると中国語の意味が全く分からないので本当に困りました💦
これを解決する方法は2つ
1.windows homeを一度抜いて、入れなおす方法
2.windows proにアップグレードする方法
結局、調べてみたけど1の方法はとてもめんどくさそうので、いつかhyper-vを使うと自分に言い聞かせwindows proを購入
そしたら、日本語をダウンロードでき解決しました。
ただやっぱり、再起動するときなど、一瞬中国語が出るのでああもとの中国版を上書きできないよなあ。。。と思いつつ、まあ作業にはまったく支障がないので一応解決としてます。
だるいその5(中国のネット経由で重いファイルダウンロードできない)
新しいwindows PC買ったし、開発用の環境を構築しようとした時に早速問題にぶち当たった。
なぜかdockerのホームページからdocker for desktop windowsがダウンロードできない。正確に言うと、ダウンロード途中に重すぎてエラーになる。
こういう中国独自の問題を解決するにはこちらのサイトがおすすめだ。
基本全部中国語だが、英語や日本語で調べても出てこない中国独自の問題の解決策が中国版stack overflow的な感じで載っている。
このサイトによると迅雷(xunlei)or 百度网盘を通して入れる必要があると知る。
とりあえず、迅雷を入れてダウンロードするとエラーなく普通にダウンロードできた!
これにより、wsl2上にdockerを入れることができた!
だるいその6(中国のネット経由でgit cloneができない)
早速、Ubuntuも入れたしmacbookで開発してたリポジトリをcloneして持ってこようとしたらまさかのダウンロードができないというか全然receiving objectsができないことが発覚。
その場合こちらの中国国内用のミラーサーバーを通して、git cloneしないといけない。
こちらのcnpmjsミラーでgit cloneしたらいけました!
例)
- //普通のgit clone
- //中国国内でcloneする場合
だるいその7(中国のネット経由でnpm installができない)
git cloneした後に、node_moduleを入れるためにnpm installしたけど、相変わらず途中でgitからのダウンロード時に止まってしまう。
また、直接、cnpmjsを使えたらいいけどやり方もよくわからない。
そういう場合、npm config listでregistry を確認しよう。
おそらく、デフォルトではhttps://registry.npmjs.org/になってるはずだから
そこに、中国のネットショッピングサイトで有名なtaobaoのミラーサーバーを使う
npm config set registry https://registry.npm.taobao.org
これでnpm installしたらいけた。
これにて、やっと開発環境を構築できました!!
だるいその8(debian系のパッケージインストールがめっちゃ遅い)
中国にいるときパッケージインストールする場合もミラーが必要になります。
この場合はsources.listにミラーを設定する。
まずはバックアップをしておく
sudo cp /etc/apt/sources.list /etc/apt/sources.list_backup
sources.listの書き換え
sudo vim /etc/apt/sources.list
aliyun(アリババ)のミラーをぶっこむ
deb http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse
そして更新で完了
sudo apt-get update
sudo apt-get upgrade
だるいその9(anacondaのcondaが遅い)
中国の精華大学のミラーを使用する
チャンネルを加えるとダウンロード速度が上がる
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/conda config --get channels
で確認して、追加されていたら完了
だるいその10(仮想環境用のwindows 10 ios ファイルがバグる)←今ここ
ちょっとグレーな中国アプリを使う環境用に、hyper-vにwindows osの仮想環境を作ろうとしたがVPNなしだとwindows 10のiosファイルをダウンロードが完了した瞬間ハッシュ値が合わずダウンロードがキャンセルされる。
VPNありだとダウンロードできるが、hyper-vで仮想環境を立ち上げた瞬間にbootエラーでisoファイルが正常じゃないと怒られる
運よく、急用で必要になるはずのグレーアプリが今のところ不要になったのでとりあえず放置してます。
まあ、できるだけ早く解決しないと色々不便だなあ。
ミラーサイトを乗っけておきます
ということで、本当にめんどくさい!
まとめ
なので、みなさん中国にきて開発をするときは覚悟してくださいということで
まあ、どちらにしろ僕は当分の間日本に帰れないのでそういう中国ならではの方法をいっぱい探していこうと思います。
これからも、そういうことに興味ある方はよかったら見てください
以上中国でリモートワークはしんどいぞということでした
無駄に長文になってしまった文章読んでいただき、ありがとうございました(^^)/
後、9月27日のおんやる当日にもオンデマンドで中国ネタについて話すのでよかったら見てみてください!!
ほかにもいろいろ面白い項目があるのでオンやるをチェックしてみてくださいね!!
他にも
・「量子コンピューターを触ってみた」ゆっくり実況(オンデマンド)
・コロナ時代の家計簿作成 with google tools(オンデマンド)
・日本に帰れなくなったふむひみが語る中国ネタ(生配信)
・日本に帰れなくなったふむひみが語る中国ネタ - 外伝(生配信終了後オンやるサイトにリンクが入ります)
・アドベントカレンダー(サイト掲載)
やってるのでよかったら見てくださいね!!
臆病者のナンパ分析

どうも日本脱出系のふむひみですっ
今日は受けるかはわからないがこれも自分らしさということで拗らせ系コンテンツを投稿しようと思う。
好きな人は好きだし、嫌いな人は嫌いなコンテンツになると思うので見たくない人はそっ閉じしてください笑
昨日までyoutube投稿と双極性障害の相性の悪さもあって落ち込んでいたそして、まあナンパにも行ったわけだがもちろん2時間地蔵をしただけだった。
なので、反省込みネタ込み次に活かす込みでブログにする⭐️
過去
女性コンプレックスを拗らせた
きもいかもしれないが、小学校の時に好きな女の子がいて告白できなかった。
その時に、男子校入学後に告白を試み男子校受験を試みるが馬鹿な僕は受験に落ちまくり、共学の中学校に入ってしまう。
そこで女には話しかけないという謎の制約を自分にかけてしまう。
そこから女性コンプレックスを拗らせた。
んで、彼女はできても手すら繋がないなどが続く。
遺伝子的に臆病者 内向思考なのは仕方ない。
現状
少し女遊びなるものに憧れるが引きこもりかつ拗らせ系男子にはきつい模様と判断
とりあえず、今 中国で男友達もいなければ女友達もいないのでナンパをしてでも何かしらつながりを作ろうと決断
とりあえず、普通にナンパを試みるももちろん失敗
なので、グーグルフォームを使った調査型ナンパ法を思いつく
されど、結局昨日落ち込んでいたからかやっぱり今日も飯だけ食って帰ってきてしまった。
なので、今日から臆病者なのを認めて徹底的に追究しようと思う
今回はストリートナンパをメインに考えていきます。
アプリなどもありますが、今回は自分の弱点克服も含めてストナンで考えていきますっ
対策
俺目線
行く前から無理と思ってる
→解決方法
思考停止する
酒を飲む
睡眠不足にする
頭にプログラミングなどで負荷をかける
別の事柄で成功体験を積んでから行く
ストレスのかからない作業をおわらしてすっきりして行く
ランニングして、筋トレしてシャワー浴びて瞑想してから行くなどなど
初めの声かけができない
→とりあえず、いろんな人に話しかけるようにする。
ナンパの準備運動の前に、老若男女含めて合計30人に声をかけながらナンパする地点に向かう
難易度
道に迷った系から
今日天気がいいな系までなんでも試す
無理だったら
罰を用意する
→次につながるもの(声かけのシミュレーションや初動の声)
日一回 道を訪ねる
→とある一個の店を訪ねる
その他
・一人の暇そうな奴を探す
・待ち合わせ女子を探す(まずは店を知ってるか聞く こっちも待ち合わせしてることを伝える)
露出度高め、過度に外を意識してる女子を狙う
靴がボロボロ
周りの視線が気になる
→暴露法で道のど真ん中でいきなり歌う しかも日本語でw
(実際にやってる奴がおるが彼が何を考えてるかは不明 あと、周りはドン引きな模様)
人目を気にするのは脳のCPUが余剰分あるからと仮定する
それに代わるCPUなおかつ不安を生じないものに置き換える。
例えば500-13を脳内で繰り返し、それまでに女の子に話しかけないといけないというルールを自分にかす(東京グール風) 引き算結果を口から出すのでもいい。
自分に意識が向く
女性目線
とりあえず、店を訪ねて一緒に行く? んで飯一緒に食わん?からの無理やったら連絡先だけでもパティーン
とりあえず、 共感を意識する。
道を尋ねるだけでもいいが長時間会話からの次に繋げれるように楽しく話す
→今天跟你讲话我很开心下次你有时间的时候一起去喝茶好吗?
(話してて楽しかったから、今度よかったらお茶でもイコー的な)
結論
臆病者には臆病者のやり方がある。
「臆病者には臆病者の生き方がある。
おめえが苦しんでるのは、臆病者の自分から、なんとか逃げ出したいと思っているからだ。
どんな手を使ってでも逃げ出したいと思っているからだ。
だが、それは本当じゃねえ。
臆病者の自分を大切にしてやる道が、どこかにきっとあるはずだ。
臆病者の自分から逃げちゃいけねえ。
一度逃げれば、一生逃げ続けることになる。」
臆病なりに、ほん気で生きよう。
ナンパが無理なら研究しよう
臆病には臆病の生き方を!!
2020年タスク管理のtrelloで人生管理

今日は皆さんもご存知のトレロについて動画説明して
行こうと思います。
トレロを活用すれば、仕事でのタスク管理だけでなく
個人の人生管理ができるので実戦活用していきます。
1トレロ導入部分
a.挨拶
aa.トレロはタスク管理ツール・トレロダウンロードのURLは下に載ってあるリンク
b.2020年になったし、タスク管理から一気に人生管理してみよう
2基本的な使い方
a.まずはサンプル
(todo→進行中→完了→アーカイブに関しての説明)
3人生管理に関して(大きなタスク管理)
a.僕の場合それらを三つの大きなタスクに分割した
b.今のやるべきこと・死ぬまでに成し遂げたいこと
(ライフタスクに近い)・死ぬまでしたいこと(娯楽)に
分けれる
4まずは今のするべきことに関して
(興味があること これから頑張りたいことでもいい)
a.僕の場合なら技術・国際交流・インフルエンス系に分けられるから3つのボードに分ける
*
エンジニア→技術系とsns
営業→ビジネス系と投資とか
b.それぞれ現在やっていることややることを書く
(ここに書くのはほぼ確定事項にするべき)
*確定事項でないことは成し遂げたいリストか
ステッキーズにかく(後ほど説明する)
5.成し遂げたいことについて
a.前に説明した今のするべきことの確定事項でないことでもいい
b.他にも単純に夢ややりたかったこととかでもいい
自分が成し遂げたいと一ミリでも思うものをかく
どちらかといえば乗り越えたい壁みたいなイメージ
*写真を乗っけるとモチベアップにつながるかも
6.バケットリストについて
成し遂げたいこととは逆に、娯楽に関して
スカイダイビング死ぬまでにはしたいな〜程度
7.それらをweekly タスクに区分していく
weekly taskの説明
a.月曜日~日曜日までと実行中と完了があればいい。
b.毎週ごとにタスク管理する
出来るだけ事前に決めておく
c.フラグについてそれぞれ説明
c1.思考 比較的考える
c2.リサーチ 比較的ググる
c3.技術
c4.情報発信
c5.ビジネス
c6.外注
8.planywayの説明
a.ガントチャートを表示できる
タスク管理やスケジュール管理には必須
b.無料版で基本的にいけるけど、有料版なら全ボードと
マイルストーンをおくことができる
(マイルストーンはタスクの中間目標地点→でもマイルストーンフラグを使ったら代用できる)
マイルストーン フラグについて
9.ステッキーズに思いついたことや忘れてはいけないことを書く
些細なことはメモや思いつき
その他今のタスクに関連することで比較的小さくなおかつするかどうか定かでないもの
10.毎月のお金をスプレッドシートに送るようにする
次の動画へ
金銭管理で毎月使用金額を確認
→何に使ったのかのグラフ
これについての説明は次の動画で~spread sheetについて~