2020深セン情報まとめ
*youtubeにまとめました よければチェックしてみてください⭐️
どうも日本脱出系YouTuberの
ふむひみです
今日は話題の深センについてまとめて
行こうと思います。
いわゆる中国の経済特区である
広東省深圳市について紹介していこうと
思います。
深センは現在4つある経済特区の中で
一番早く1980年8月に指定されました
他の経済特区は珠海、汕头、厦门という感じです。
(深セン、珠海、汕头は広東省で
厦门は福建省にあります。)
深センの歴史
説明していこうと思います。
1840年のイギリスと中国間のアヘン戦争により香港はイギリス領として植民地化されました。
それにより中国と香港の道は大きく二つに分かれ、1949年10月1日に
中華人民共和国になってたのも含めより異なる方向へ向かうことになりました。
そこから経済特区に指定されるまでの30年間大陸側では共産党の大躍進政策や文化大革命により大規模な武力闘争や飢饉が続き、闘争に破れた人達やその他貧しい人達がより生活が豊かな香港に逃げ始めました。
1957年/1962年/972年/1979年と4回大きな香港逃亡がありました。
政府側はなんとか食い止めようとしましたが、逃亡阻止は厳しく、香港に負けない経済特区を作り経済的に開放する改革で自国民の逃亡を止めようとしたのが始まりと言われています。
1980年あたりは330平方キロメートルでしたが、この40年でおよそ7倍ほど大きさを広げ、今では小さな漁村だった深センから中国のシリコンバレーとまで呼ばれるように発展しました。
深センの基本情報
出典:
https://baike.baidu.com/item/%E6%B7%B1%E5%9C%B3/140588?fr=aladdin
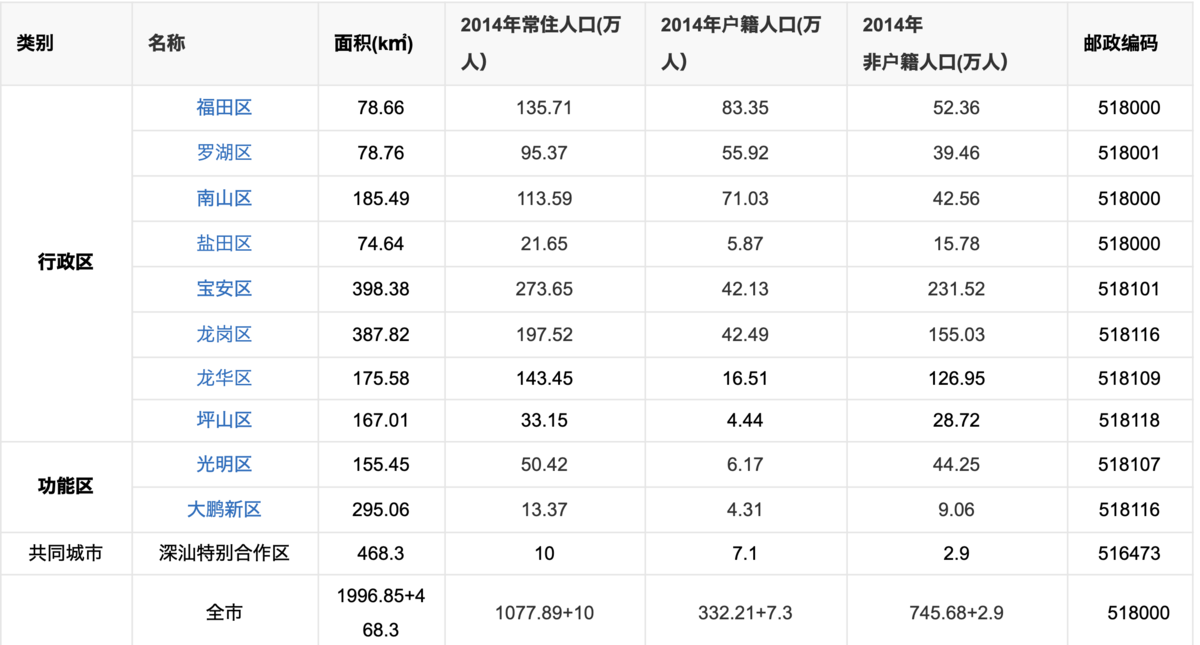
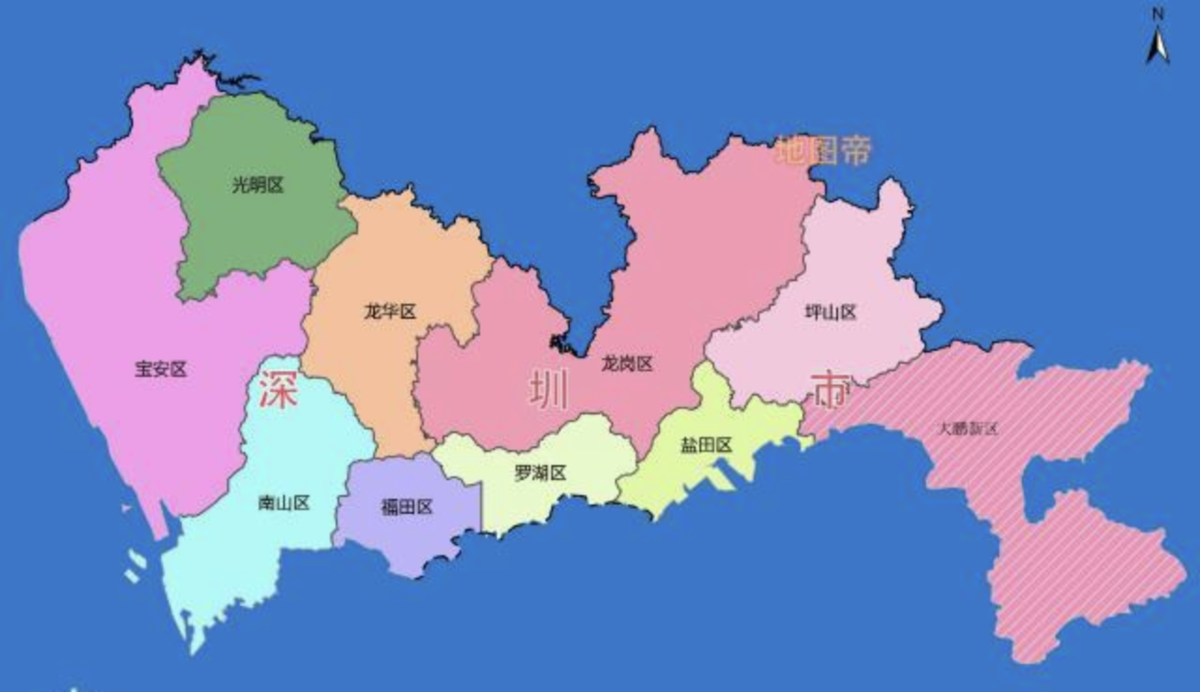
深セン区別マップ 出典:
面積は約2000平方キロメートルで東京とほぼ同じ大きさ
人口は約1300万人で東京都同じくらい
東京都のGDPは94兆円
東京の平均年齢が45歳ほどに対し、深センの平均年齢は32歳ほど
平均給料は約5000元(約8万円)
生活費は約3000元(約4万5千円)
市区別基本情報
深センはそれぞれの区によって特色が違います
その特色について僕個人的な意見とネット上の意見を合わせて書いていこうと思います。(あくまで個人の意見の範囲です)
福田区

生活に便利で居住に適した場所
中国のthe高度成長を代表する高層ビルのイメージ
平地が多く、新しいものが多い
深センの政府の中心地
金融の中心
地理的に深センの中心地
罗湖区

全国改革の原点
昔ながらの街が多い
香港の昔ながらの街に似ているし、近い
生活水準が香港とほぼ同じ
道が基本的に広くない
南山区

深セン内で最も裕福
深セン大学
テンセント
高科技产业园がある(最先端技術を研究開発している場所)
IT企業が多い
海辺の観光地が多い
盐田区

山が多く、 荒涼地帯、水上輸送の中心地、山や海の資源が多い
レジャー施設が多い
旅行には最適
宝安区

都市と農村部の結合部分
空港がある
ビルが古いイメージ
海が近い
龙岗区

大きい
人が少ない
中心地から遠い
アクセスがよくない
龙华区

元宝安区の一部
新しい
中小企業が多い
潜在的な発展地域
坪山区
坪山区

元龙岗区の一部
比亚迪(有名ハイブリットカー企業)がある
潜在的な発展地域
大鹏区
大鹏区
出典:http://www.sznews.com/news/content/2018-12/30/content_21317666.htm

元龙岗区の一部
自然が一番多く歴史文化資源が比較的多く集中している
光明区
光明区

元宝安区の一部
教育基盤が多い
製造業が多い
緑が多い
区それぞれの GDPの変化
https://www.bilibili.com/video/av28716109/
深センの特徴
深センの近くには香港があり、交通が便利で気温は穏やか、景色はきれい、外資系の経済が発展してる
工業技術、貿易、農業、住宅、観光など多くの特性を兼ね備えた都市である
土地的には香港と近いのもあって、広東語が話されると思いがちだが実は中国からの移民が多いので案外北京語(普通語)で通ってる。
有名な言葉で"来啦就深圳人"
「来たらもう深セン人だ」というなんともウェルカムな言葉が
あるぐらいだ
深センの変化 1980-2015
深セン南山区の変化(1985-2015)

深センの路線図ごとの特色

ネットの情報をまとめて書いてみました
ちょっと古い情報もあるので、違ってる場合があるかもしれません
ご了承ください
社会先行型モデル
去年に社会先行型モデルとして認められている
深センは元より実験的に開放した部分があり成功したので、深センをモデルに他の中国の都市も開発していくようになった
また、これからも深センに政府が先行投資をするようだ
詳細はこちら↓
深センでの生活
QR決済について
現在(2020年1月)メインの決済はwechat payとalipayですが wechat payは中国の銀行カード以外利用不可なので、Alipayを使うようにしましょう。
Alipay内のプログラム'TourPass'によって外国人でも利用可能になってるのでそれを使うべきです。
僕は去年中国移動のSIMを契約したのですが、その場合TourPassミニプログラムが使えなかったので中国外で買うか旅行用SIMを買う方がいいかもしれません
後、現金ですが2年前ほど僕が初めて深センに行った時は現金を用意してる店が比較的少なく、現金を渡して代わりに店員さんに払ってもらうなど
結構面倒くさかったのですが今ではお釣りを用意してる店が多いので現金だけでも生活していけます。
路線の変化と新幹線のアクセス
2020年以降に深セン大地鉄時代が来ると言われている現在さらに12本に同時建設中であり、乗り換え駅が39個新しい駅が85個生まれる予定です。 また、今後の3年で盐田区、光明区に行く線が増える模様
自転車シェアリング
今のところ生き残ってるのは摩拜、ofo、哈罗ぐらい
結構もてはやされたシェアリング自転車ですが、今では使用者が激減しメインで残っているのも上記3つだけ
今後、もっと減っていくかもしれない
去年の10月ごろに南山区でシェアリング自転車の営業停止になり、原因として借金をしてインフラ投資した割に利用者が少なくコストが無駄にかかるから
充電器シェアリング
シェアリング充電器ボックス
これも現金では無理なので注意してください
QRペイで保証金含めた額を払って戻したら、保証金が返される仕組みです。最近どこでも良く見かける。
とりあえず、傘からオフィスまでなんでもシェアだ。
おそらくシェアの文化は資本主義ではなく、共産主義的もしくは社会的主義が故に来る概念だと思う。だからなんでもシェアにする。
顔認証
僕はまだやったことないけど、顔認証でコンビニでものが買える。
僕はまだQRコードで払ってます汗。
VPNについて
中国ではグレートファイアフォールによって中国以外のネットは使えないので、VPNは必須です。
まずは中国にいく前に設定することをおすすめします。
中国からアクセスできるVPNのサイトやアプリはほぼ死んでて時間を無駄にするだけです。
2度言います。まず日本で設定してからいきましょう。
後、どれも1,2ヶ月ほどお試し期間があるのでバリバリ使っていくことをおすすめします。
カスペルスキー セキュアコネクション
スマホとPC(macbook)ともに使えるが、速度が遅いだが安い
ExpressVPN
WIFIに繋いだ状態だ状態での速度は使用してる中で最速。
ずっと家にいるなら、こっちの方がいいけど少しでも外でfacebookとかチェックしたい人は考えた方がいい
後、日本のVPNは基本的に繋がらないからアメリカとかシンガポール経由とかになる
セカイVPN
今使ってるやつ
はてなブログは日本経由のVPNじゃないとforbiddenされるから
結局日本のVPNを使うようにした。
expressVPNで日本を選択できないのはだいぶ痛かった。
今はお試し中でもし契約したら料金は比較的高いが、とりあえず落ち着いた
VPNの種類は基本的にOpenConnectをおすすめします。
自己紹介とこれから
現在、所用で福建省にいますけど来月から深圳にいく予定です。
でもまだ今年で通信大学4年生になり、後1年間学生生活しなければいけないので深圳に住みながら香港で週3回ワーキングホリデーします(時給100HKぐらいほしい)
後個人的に、この半年はミニプログラムの開発を中国人サイドとやって行こうと思ってます。
こちらに自己紹介があります。
お仕事の依頼など何でも屋してるのでよければ、お話だけでもください
よろしくお願いします😃
後よければ中国にいる日本人の方々、友達になってください笑
ということで終わります。
最後まで読んでくださってありがとうございました。
また、youtubeと個人のビジネスの方頑張ります。
お疲れ様でした。
ふむひみ【日本脱出系youtuber】のプロフィール
カルロス・ゴーンの現在と日本社会

どうも!
日本脱出系youtuberことふむひみです!!
よければフォローとチャンネル登録よろしくお願いします!!

ふむひみ君のアカウントを解説しました!これから有益な動画や情報を発信していくのでよろしくお願いします!#日本脱出 #ふむひみ#自己防衛#投資#海外移住#深セン #サイバー大学
今日は世間を賑わしてる
カルロス・ゴーンについて夜の記者会見前にまとめていこうと思います
まずはホリエモンのカルロス・ゴーンに対する考え方を YouTube を見てまとめようと思います。
・カルロス・ゴーン第1弾 (2019/12/31)
こちらの動画はほぼカルロスゴーン氏が逃亡したばかりの状況なので、どうなるのかという話が挙げられています。
etc.)
・いつの間にかレバノンに逃亡していた
・おそらく有罪なら80歳以降に出所することになる
・カルロスゴーンは外国人なので、国外の逃亡の恐れがあった。
・ホリエモンとカルロスゴーンは合う予定だった
→今後もしかしたら、レバノンで対談が実現するかもしれない
・日産の経営陣と検察側においてどうなるか不明だった
・プライベートジェットにのっていた
こちらの情報が上がりました
・カルロス・ゴーン第2弾(2020/01/02)
こちらの動画では
etc)
・カルロス・ゴーンの逃走ルート
トルコ経由でレバノン入りしたこと
・トルコからレバノンに行くにかけて、
プライベートジェットも位置情報でトレースできたのに
日本の方は遅れてしまったこと
・プライベートでは大きい荷物では荷物検査されることがなかいことがあり実際にそれによりゴーンさんが逃げた疑いが高いこと
(入国管理の杜撰さ)
・金融商品取引法違反(証券の発行や売買に関しての法律)
もらうはずだった報酬の半分を有価証券報告書に記載せずあとから
もらう契約をしたことにより捕まった
↓
またその後保釈されたが業務上横領で逮捕起訴された
*有罪無罪のこの決定する部分は金融商取引法ではすごい曖昧
つまり、巨額の金額における数億の記載漏れはそこまで全体額に
比べて大きくないので、金融商品取引法違反においての判断が曖昧
・村木厚子さんの郵便不正事件の例
無実の人を100日以上も人質司法で逮捕拘留した(第4弾で説明)
検察側の立場が強すぎるがゆえに起こる冤罪
・司法取引制度(第3弾で詳しく説明)
誰かの罪を話す代わりに、自分の罪を軽くできる取引法
日産の西川さんがこの制度を使って一方的に自分は無罪でゴーンとテリーを有罪起訴に追い込んだ
↓
不平等な手法
他の国ではどっちも基本的に司法取引ができるが今回は西川さんだけでゴーンさんは無理だった
・カルロス・ゴーン第3弾(2020/01/03)
東国原さんがバカすぎるので三権分立について話します。カルロス・ゴーン解説第3弾
第3弾から第5弾にかけて重複してる内容が増えますので、さらっとまとめます。
etc)
・そもそも東国原さんが弁護士を避難することは馬鹿
↓
なぜなら
昔の日本では三権分立は不完全だった
当時の日本では司法の中に検察と裁判所があった
だから三権分立は不完全で無実の罪なのが生まれた
無実の人を処罰していた
弁護士は世論などや冤罪から無罪の人を守るために、
守る人を作っている
弁護士に責任があるって言う東国原とテレビは間違ってる
・昔の日本では三権分立がうまくなされていなかった
司法として検察と裁判が同じ部門に入っていた
その時も現在同様に検察側は立場が高かった
また治安維持法がゆえに、
無罪の人や多くの思想犯罪者が投獄された
を使って処罰などしていた
が最終的に全部特高警察のせいになり、
歴史では特高警察が悪者として残っている
・カルロスゴーンの心境について
カルロスゴーンはもし日本に居れば、
80歳まで刑務所生活することになるだろうし獄死するぐらいなら
日本の司法制度に対して抗議をし自分が思う正しい正義をもとに
抗議をすると言うことなんだろう
死んだら終わりだから、
彼の正義に従って自分の国に帰って
レバノンなどの国民の倫理に訴えかける
日本人だけの世論から英語圏の世の中に
行ってアピールしに行ったのだろう
・カルロス・ゴーン第4弾(2020/01/04)
カルロス・ゴーンが見た、日本の腐った司法システムについてお話します【ゴーン第4弾】
etc)
・容疑を否認しても保釈されない司法システム
日本の司法では
刑事訴訟法第89条4項(証拠隠滅及び逃亡のおそれがある場合)により
起訴されても、保釈されないことがある
それを起訴後拘留制度という
これにより長期に渡って幽閉される形になるため精神的にだいぶきついらしい(ホリエモンが精神薬飲むレベル。。。)
・司法に関してほとんど国民は知らない
国民は刑事司法を知るわけないから検察側がいいようにやってる
日本メディアと検察がつながっているので、普通人権の問題が上がりそうなのにメディアは報道をしない
そして、世論が偏る
それにより、謎の弁護士叩きや一方的にゴーンだけを悪とする報道が流れる
・カルロスゴーンの海外逃亡のきっかけ
この状態まではよかった
この時までカルロス・ゴーンはおそらく普通に日本で罪を認める方針だったのだろう
高野さん(弁護士)との話し合いで、しっかり最後は引き続き頑張っていこうという話をされていた
だが、日本の長期拘留時に、奥さんと会えなくなることそしてそれが何年続くかわからないことが知らされたことがゴーン逃亡のきっかけになった
奥さんも共犯者と定義され、何回もお願いした上でやっと弁護士同席の上でクリスマスイブにズーム(オンライン会議アプリ)で1時間だけ話し合えた
また何年続くかわからない裁判が終わるまで会うことができないという取り決めをされてしまった
奥さんと会うことができないという
前近代的な司法は日本だけ他の国ではありえない。
ということでゴーンさんオコでエグザイルわず
ちなみに、日本の司法の現状とゴーンさんの心境が書かれたブログ
はこちらは
弁護士の高野さんのブログ
カルロス・ゴーン第5弾 (2020/01/07)
日本の悪しき伝統「人質司法」について解説します【カルロス・ゴーン第5弾】
人質司法について解説
etc)
・日本の悪しき伝統「人質司法」
日本独自の手法で本来身柄の拘束をする必要性がない
被疑者を長期にわたって拘束するような方法
刑事司法の悪しき伝統とも呼ばれている
何でゴーンが逃げたのか
普通の先進国では見られない身柄拘束の方法
本来必要ない人にも拘束してしまうから
・村木厚子さんの例について
検事の捏造により長い間拘束された
冤罪で100日以上大阪拘留所に勾留される事例があった
検事は毎回罪を立証するときに、ある程度の犯罪シナリオを組み立てた上で被告人を尋問する
そして、罪の内容をシナリオに当てはめて行くらしい
それにより、村木厚子さんの場合は捏造された証拠品が使われ結果無罪を勝ち取ったものの長期間拘束される形となった
こちらは世界仰天ニュースで2017年放送された時の内容です。
・日本版司法取引制度
日本でも司法取引制度が導入されたが、今回奇妙な点はゴーンさんと西川さんの両方ができるはずの司法取引が西川さんにのみ適応され、ゴーンさんとテリーさんが捕まった件だ
司法取引制度とは共犯者もしくは他人の罪の証拠などを提供する代わりに自分の罪を減刑もしくは無罪にしてもらえるものである
本来両側交渉できないとおかしいのに、片方だけが取引できている。
まとめ
現時点でわかってること
・ゴーンがルノーと日産の統合を提案したことで追い出されたと主張
・ゴーンはレバノン政府に助けられ出国したとの噂
・フランス政府と結託して、ゴーンが日産とフランスの車会社を統合しようとして日本政府が止めるためにゴーンを吊し上げたという噂
・ゴーンの奥さんも自分の会社を持っており、そこにゴーンさんのお金が流れた疑いがあり現在奥さんの方の逮捕状も取ったということ
今日の夜全ての真相(ゴーン視点)がわかる
結局このゴーンさんの問題は痴漢冤罪と同様に一度嫌疑をかけられたらもう一発アウトなのが問題
認めたら痴漢だし、認めなかったら認めるまで人質司法により拘留され続けメンタルブレイクされる。
会社はもちろん家族にすら会うことができない。
検察側に有利な進め方
司法取引制度によって一方的に無罪有罪となる
勾留時間が長い間人質司法
まあホリエモンさんの個人的な日本との確執とかあるんだろうなと思うけど、
日本のよくない一面に今回を気に光が当たったことはいいことだと思う。
日本は変化を恐れすぎてるからよりいい国になるよう成長しないと日本に未来はない。
今ではゴーンさんが日本脱出してから、保釈された人にGPSをつけるなど話が上がってるけどなぜ今までしなかったんだろうっていう。。。
今後GPSを付けられる代わりに、保釈される人が増えるかもしれない。
こちらが後日、youtube動画作成後にまとめた動画になります。
よければ見て見てください!!
最後まで読んでくださってありがとうございます。
ブログ再開宣言ですうううっ
どうもふむひみですっ⭐
会社辞めてから約3ヶ月が経ったけど、その間全くブログを書いてなかった汗💦
twiiterにリンク貼ってたのにね。。。
でも心入れ替えました
というか考えを変えましたっ😀
もう2020年になるし、ブログオワコンだろって言われるかもしれません!
それでも今日から出来るだけ毎日書いて行こうと思いますっ
読者になってくれる方居ればよろしくお願いします🙇♂️
僕のことを知らない人も多いので、こっちで軽く自己紹介してますっ
よければ御確認ください🌞
明日には運営している
サイバー大学グローバル交流部に関して書こうと思います
よかったら見てくださいね!
またこれから他の人に共有したいと思う記事が有ったら、
シェアをよろしくお願いします🙇♂️
双極性障害により会社をクビになったが、日本脱出しようと思う件

自己紹介
中学時代から野外放浪(ホームレス)と引きこもりを
繰り返す双極性障害
↓
関西の大学に入学し大学2年生の時に休学、
香港と中国で英語・中国語を使って3ヶ月の営業インターン
↓
↓
↓
上京を決断して東京に進出しWeb系に就職したもの
双極性障害で退社
↓
今ココ(絶望) *9月時点
最近の出来事 (9月時点)
今年はデータサイエンティストを目指しながら、会社でWEB開発とスクレイピングの案件をさせてもらっていました。
でも、僕自身が双極による体調不良により、休みが増えた結果会社に居ずらくなってしまい自主退社。。。乙
(一応、デパケンというの薬を飲んでましたし、結構長期で治療をしてもう大丈夫だと思って自信を持って就職したのですがやはり無理でした。)
前の会社の人にはわざわざ特待生で雇ってもらったのに、こういう形で退職することになり本当に申し訳ないことをしたなと思ってます。
それと同時に双極性障害がある自分は
「普通に働くことはできない」と悟ってしまいました。
自分では結構普通に合わせようと努力したつもりでしたが、薬を飲んでも自分の人格が別のものになってしまった感覚や意識しても帰ることの出来ないミスや不注意などがあったからです。
僕はもう日本を脱出して
海外で自分らしく生きて行こうって決めました
これからの人生 (9月時点)
自分らしく生きるって何するねんって話ですけど、とりあえず自分ができることをするのみです
自分が1ミリでもできること全てに手を出して
双極性障害・ADHD・ニートの三拍子が揃った僕ですがなんとかこの世の中で下克上してみせますよ!
ブログで収益化とかそこまで期待してないです
自分という人間がこの世の中でコンテンツになってそれをみんなが楽しんでくれたらいいです。
そして多くの人と繋がり、 人生楽しく生きていけたらいいです。
滞在予定
偶然同じ国にいるなら
無料で英語・中国語のレンタル通訳マンをします(笑)
よければ連絡ください笑
*本来12月は台湾にいく予定だったのですが、深センには欲しいものが全てあったので台湾旅行をキャンセルして深セン生活を送ることにします!!
発信情報一覧
今後、発信していくであろう情報一覧です。
- 日本脱出して生活していく情報
- ホームレス・ニートとして生きていく方法
- 元ホームレスとしてホームレス社会をもっと良くしたい
- 双極性障害・ADHDに関して
- プログラミング系
- 英語・中国語や海外に関する情報
- 海外のストリートアートやグラフィティアート
- 俺的風刺画アレンジ
そういえば、今日はクリスマス・イブですね🎅
みなさんいい1日をお送りください🦌✨✨✨✨
最後まで読んでくださってありがとうございます。
元ホームレスが機械学習とディープラーニングをしてみた
どうもお久しぶり! ホームレスのhumuです。
最近忙しかったのと、Qiita記事に浮気をしていたのであまり投稿出来てなかったですw。
今回は最近流行りの機械学習とディープラーニングをしていこうと思います!
使うデータはkaggleコンペティションにあるIMDBデータ!
こちらのデータは過去10年間にIMDB(internet movie database)で2006年から2016年の人気のあった映画1000本が用意されてます。
今回はそのデータを使って映画のレビューから映画に対して肯定的な意見か否定的な意見かを判定し予測するモデル(AI的な何かw)を作ります。
では、手を動かしながらやっていきます!
まずはデータ分析で使われるpandas 、numpyやデータ可視化のmatplotlib、ディレクトリ操作のosなどのライブラリを入れていきます。
import pandas as pd
import numpy as np
import os
from IPython.display import HTML
import matplotlib.pyplot as plt
%matplotlib inline
import japanize_matplotlib
ファイル読み込み
分析のためにデータをわかりやすくpandas のDataFrame型に整形する関数を定義します。
今回は、0~10までの評価値がレビューに付与されているので肯定or否定に分けるので
7以上を肯定つまり1,4以下を否定つまり0としてラベル付けします。(中間値となるものは元からデータ側で分けれていますのでご安心ください。)
def mk_dataframe(path):
"""
pathに元ずいてdataframeを作る。
path:str
train or test/pos or neg
files:list
text data to read
"""
data = []
files = [x for x in os.listdir(path)
if x.endswith('.txt') ]
for text_name in files:
# ファイルを読み込む
with open(path+text_name,'r') as text_data:
text = text_data.read()
# IDとreview読み込み
text_num = text_name.rstrip('.txt')
ID,review = text_num.split('_')
# バイナリー値の代入
if int(review) >= 7:
label = "1"
elif int(review) <= 4:
label = "0"
else:
label = ""
data.append([ID,review,label,text])
df = pd.DataFrame(data,
columns=['ID','review','label','text']
,index=None)
return df
kaggleのデータセットから持ってきた訓練用とテスト用のnegative positiveのデータをそれぞれデータフレームとして変更します
# それぞれのデータを読み込む
train_pos_df
= mk_dataframe('../aclImdb/train/pos/')
train_neg_df
= mk_dataframe('../aclImdb/train/neg/')
test_pos_df
= mk_dataframe('../aclImdb/test/pos/')
test_neg_df
= mk_dataframe('../aclImdb/test/neg/')
また、後でデータを分割した時値が固まらないようにデータフレームをシャッフルするような関数を定義します。
同時にネガティブなデータとポジティブなデータを結合します。
def shuffle_data(pos_data,neg_data):
'''
posとnegのdataframeを結合する
'''
full_df = pd.concat([pos_data,neg_data]
).sample(frac=1,random_state=1)
return full_df
# 訓練用とテスト用データの作成
train_df = shuffle_data(train_pos_df
,train_neg_df)
test_df = shuffle_data(test_pos_df,test_neg_df)
train_df.shape,test_df.shape
train_df.head(10)

一行目のtrain_dfの文章を出力します。
# 文章のサンプル表示
HTML(train_df.text.iloc[0])

固有の評価数とラベル数を分析します。
# ユニークな評価数 ラベル数
print('review:\n{0}\nlabel:\n{1}'.format(
train_df.review.value_counts()
,train_df.label.value_counts()))

テキストの長さと量の分布を可視化します。
plt.figure(figsize=(15, 10))
plt.hist([len(sample)
for sample in list(train_df.text)]
,50)
plt.xlabel('テキストの長さ')
plt.ylabel('テキストの量')
plt.title('テキストの分布',color='gold')
plt.show()

前処理(labelを使う場合)
ここからデータを綺麗にするための必要となるデータクレンジングや前処理をしていきます。
まずは上記にあったデータを予測する(文章から肯定か否定か)ための特徴量(X)と出力結果(肯定か否定か)であるラベル(y)に分割します。
# X,yにデータを分ける
train_data = train_df.iloc[:,2:]
train_X = train_df.iloc[:,3].values
train_y = train_df.iloc[:,2].values
print(train_y.shape)
train_y.shapeの結果は(25000,)で25000個の出力結果があったことが伺えます。
次にone-hotエンコーディングをすることでカテゴリ変数(ここではレビュー内の単語)を機械がデータを理解しやすい形に整形します。
from sklearn.feature_extraction.text
import CountVectorizer
CountVector = CountVectorizer()
docs = train_X
bag = CountVector.fit_transform(docs)
print(CountVector.vocabulary_)

それぞれの特徴量の形状を出力します。
# # ダミー化させた特徴量の抽出
train_X_features = bag.toarray()
print(train_X_features.shape)
結果:(25000,74849)
それぞれのボキャブラリー(単語)を出力する。
vocab = CountVector.get_feature_names()
print(vocab)
それぞれの単語の数を出力する。
ボキャブラリーとそれぞれの単語の数の対になった出力結果を出します。
print("count:word")
for word,count in zip(vocab,dist):
print("{0}:{1}".format(count,word))

機械学習モデル作成(labelを使う場合)
ここから機械学習していこうと思います。
2値分類のアルゴリズムとしてRandomForestClassifierを使います。
train_test_splitを使って、train用データを75%test用データを25%に分割します。
また評価指標のメトリクスとしてaccuracy_score,roc_auc_scoreを使います。
1.train_test_splitでX_train,X_test,y_train,y_testに分ける
2.clfに分類機を入れる
3.clf.fitでX_trainとy_trainで機械学習モデルを作成する
4.分類機でX_testを入れることでy_testの予測値であるy_predを生成する
5.accuracy_scoreでy_testとy_predの正当率を評価する
6.最後にaccuracyスコアとroc_aucスコアを予想する
from sklearn.ensemble
import RandomForestClassifier
from sklearn.model_selection
import train_test_split
from sklearn.metrics
import accuracy_score,roc_auc_score
X_train,X_test,y_train,y_test
= train_test_split(train_X_features,train_y)
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
accuracy_score =
accuracy_score(y_test.astype('int')
,y_pred.astype('int'))
roc_auc_score =
,y_pred.astype('int'))
.format(accuracy_score,roc_auc_score))
予測結果は以下でした。
accuracy_スコア:0.84464
roc_aucスコア:0.8448087599614857
Keras API 深層学習モデル作成(label使う場合)
tensorflowとkerasのバージョンを確認する
# tensorflowとkerasのバージョン確認
from __future__ import absolute_import,
division,
print_function,
unicode_literals
import tensorflow as tf
from tensorflow.keras import layers
print(tf.VERSION)
print(tf.keras.__version__)
バージョン↓↓↓
1.14.0
2.2.4-tf
1.tensorflow.kerasで入力層(Input)を用意する
2.layers.Denseで中間層を作る(活性化関数はreluを使用する)
3.出力層には活性化関数にsoftmaxを使用する
from tensorflow.keras import Input
# 入力層の作成
inputs = tf.keras.Input(shape=(74849,))
# 中間層
x = layers.Dense(64,activation='relu')(inputs)
x = layers.Dense(64,activation='relu')(inputs)
# 出力
predictions =
layers.Dense(10,activation='softmax')(x)
ではディープラーニング用のモデルを作る
1.inputとoutputの変数をモデルに指定する
2.深層学習の方法をmodel.compileで指定する(optimizerに最適化するための関数を入れる:lossに損失関数を入れる:メトリクスに評価指数を入れる)
3.深層学習のモデルに学習させる(batch_sizeはデータを一括処理する単位を入れる。:epochsに損失関数を最小にするための学習回数を入れる)
# モデル作成
model = tf.keras.Model(inputs=inputs,
outputs=predictions)
# コンパイルして学習方法を指定
model.compile(
optimizer=tf.train.RMSPropOptimizer(0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 5エポック分学習
model.fit(X_train,y_train,
batch_size=32,
epochs=5)
# train_y.shape,train_X_features.shape
Epoch 1/5
18750/18750 [==============================] - 29s 2ms/sample - loss: 0.0640 - acc: 0.9795
Epoch 2/5
18750/18750 [==============================] - 29s 2ms/sample - loss: 0.0513 - acc: 0.9837
Epoch 3/5
18750/18750 [==============================] - 27s 1ms/sample - loss: 0.0360 - acc: 0.9887
Epoch 4/5
18750/18750 [==============================] - 25s 1ms/sample - loss: 0.0263 - acc: 0.9922
Epoch 5/5
18750/18750 [==============================] - 22s 1ms/sample - loss: 0.0183 - acc: 0.9948
X_trainで学習したモデルでX_trainとy_trainを評価してみます。
そして結果は損失関数(loss)と評価結果(acc)を出力する。
今回の結果はおよそ0.99なので過学習だと思われますが今回はとりあえず、ディープラーニングをしていこうという程なので今は置いておきます。
train_score = model.evaluate(X_train,y_train)
print(train_score)
print(model.metrics_names)
18750/18750 [==============================]
- 18s 957us/sample - loss: 0.0116 - acc: 0.9967
[0.011612714384999126, 0.99674666]
['loss', 'acc']
また、損失関数でsparse_categorical_crossentropyを使ってるので、結果が指数など0,1で出ないので、numpyのround関数を使って0.5以上を1とし、0.5以下を0とする。
y_pred =
np.round(model.predict(X_test,batch_size=5))
y_pred[:10]
y_test[:10]
array(['0', '1', '1', '1', '1',
'1', '1', '1', '0', '1'], dtype=object)
ここでテストデータを使ってモデル評価をします。
test_score = model.evaluate(X_test,y_test)
print(test_score)
6250/6250 [==============================]
- 6s 891us/sample - loss: 0.1961 - acc: 0.9546
[0.19614510532215237, 0.95456]
出力結果は約0.95でした。
ほとんど予測できてますね。
こんな感じでホームレスが機械学習とディープラーニングをしていきました!
大学のテスト期間あけました!そんで、仕事も決まりました笑

お久しぶりです!
サイバー大学生三年生のhumuです!
2週間以上更新していなかったので、超久しぶりになるのですが今日からまたちょこちょこ更新していこうと思います。
とりあえず、今日は近況を報告しますと
東京にてAI専門のとあるベンチャー企業から内定をいただきました!わーい
また、給料も前の会社に比べて(まあ3ヶ月しか働いていないのですが笑),
月額5万円ほど上がるので心を新たに切り替えて立派なデータサイエンティストになれるように精進していこうと思います。
まあでも、面接で社長と1時間半ぐらい話して小学生の時から大学生の時まで聞かれて内心ドキドキしました笑
4月から仕事を始めるつもりなので、ギークハウス住民にはまたお世話になります。
宜しくお願いします。
また、4月まではほぼ大阪の実家にいるので会える人はまた会いましょう!
来週からは気分次第で、ソフトウェア工学に関してやAI関連に関しての情報を発信していくつもりなので暇な方や興味ある方は見てみてくださいね!
また、来週には旧正月の休日があけるので深センにできるだけ情報を集めに行こうと思います。
今後とも宜しくお願いします
etc
ちなみに、今日はまた長洲島の兄貴にお世話になっています笑

また、謎にこの島の高校生?の友達がいっぱいできたので、時間がある限り交流を深めていこうと思います。
また、日本語はやっぱり人気なので、機会があればみんなに日本語の学習とかさせれたらいいなあって思いました笑
